Interactive Rendering for Large City Models
By
Ali Lakhia
Motivation
- Rendering time is input dependent, not output
dependent. That is, the time it takes to render a frame is dependent
on how many vertices and triangles are in the scene and not on the
resolution of the output screen. This implies that rendering does not
scale well when the size of the scene increases.
- Rendering large models is non-interactive. In order
for a program to remain interactive, it should respond to human input
so that it is not noticeably lagging behind. For our purposes, we
define this in terms of frame rate and consider interactiveness to be
20 frames per second. However, rendering the entire city dataset
requires substantial time for the CPU and graphics pipeline.
Therefore, it is not interactive.
- Recent acquisition methods, like the acquisition
system developed at the Video and Image Processing Lab at Berkeley [3], are capable of collecting large and
detailed models. This city model has about 8,950,000
triangles. The texture consists of over 937,000,000 pixels in full
color or about 2680 MB of uncompressed data. The complexity and
quantity of data pose challenges to interactive rendering. See the
overview and closeup pictures to see the amount of detail.
Previous Work
- Discrete levels of detail (LODs), introduced by
Clark in 1974, consist of a hierarchy of objects at ever simpler
representations [1]. He used the appropriate
representations to improve interactivity.
- Funkhouser and Sequin were the first to realize
that levels of detail can be used not only to reduce the complexity of
the scene but also to limit it. They call their approach the Adaptive
Display algorithm, where they use a heuristic to determine the ratio
of cost and benefit of each object at each of its LODs. Furthermore,
they equate the graphics pipeline load management problem to the
multiple choice knapsack problem and offer an approximate solution
that is at least half as good as the optimal [4].
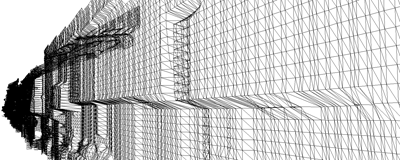
- However, rendering LODs of large objects is less
optimal. For example, consider a slanted view of a building facade
shown below. Note that a coarse representation of the object is ideal
for the portion of the object that is far away from the camera but is
too coarse near the camera. Similarly, a highly detailed LOD provides
good detail near the camera but wastes too many triangles for detail
that is not perceptible from that position. The use of a hierarchy of
LODs, or HLODs, was proposed to overcome suboptimal use of
LODs [2].
|
- Erikson et al. traverses the HLOD hierarchy
top-down and use a screen-space error metric to choose which HLODs are
refined [2]. However, the refinement process does
not directly consider the cost of each refinement and can result in
significantly non-optimal use of render times. For example, consider
an example where 4 candidates for refinement are available and one of
them has a slightly higher screen-space error. If this refined
candidate consumes the entire triangle budget while using the same
number of triangles as the other 3 replacements combined, then we get
a sub-optimal solution.
- Finally, the polygon budget is simply based on
previous frame render times, which can lead to frequent switching of
HLODs between successive frames.
Our Proposed Approach
- Our contribution is the selection process used for
refinement that is more optimal and minimizes flickering caused by
switching of detail. For details on our approach and for the results,
please review my:
References
- J. H. Clark.
Hierarchical geometric models for visible surface algorithms.
Communications of the ACM, 19(10):547-554, 1976.
- C. Erikson, D. Manocha, and W. V. Baxter, III.
HLODs for faster display of large static and dynamic environments.
In Proceedings of the 2001 symposium on Interactive 3D
graphics, pages 111-120. ACM Press, 2001.
- C. Frueh and A. Zakhor.
3D model generation for cities using aerial photographs and ground
level laser scans.
In IEEE Computer Vision and Pattern Recognition Proceedings,
volume 2.2, pages II - 31-38, 2001.
- T. A. Funkhouser and C. H.
Séquin.
Adaptive display algorithm for interactive frame rates during
visualization of complex virtual environments.
Computer Graphics, 27(Annual Conference Series):247-254,
1993.

